我的 RSS 方案与心得

使用 RSS 已经一年有余,这种对信息的主动掌握让我获取信息的质量和密度都上升了一个台阶。最早是使用 TTRSS 做服务端,安卓手机使用 FeedMe 订阅,主要订阅的是有源的商业内容站点、个人博客以及其他人分享的使用 Feed43 或 Feedburner 压制的源。随着我逐渐加大 RSS 阅读在我闲暇、琐碎时间内的比重,我对 RSS 有了更高的期望和要求,便开始了对如何构建更高效、更易用的 RSS 方案的探索。
0x01 借助 RSSHub 订阅各种热门冷门网站
RSSHub 是个很赞的项目,它聚集了众多 RSS 爱好者来为现代的网站构建 RSS 订阅源。众所周知,网站提供 RSS 并不能为他的站点带来更高的收入,反而会减少主站的访客数。借助 RSSHub 可以方便地通过 RSS 订阅知乎、豆瓣、Facebook 等现代媒体社交平台。
0x02 获取 Feed 文章全文
部分 RSS 源并不会在 xml 文件内提供文章全文,说白了是想让你点进他们的网站去浏览,这样网页上的广告才有可能被你点击。解决的方案有很多,方便起见我使用了 TTRSS 的插件 Readability 和 Mercury。两者都不能完美适配所有站点,同时启用这两者以实现互补。
0x03 无障碍阅读繁体中文 Feed
发现了几个质量不错的繁体中文信息源,主要是台湾的站点,如泛科学。由于文字和部分两岸文化差异,直接阅读繁体中文的文章有些困难。我的解决方案是使用 OpenCC 简繁转换服务,它能够对可映射的简繁汉字以及同一事物的两岸不同的表述进行翻译,输出的简体中文版文章基本可以无障碍阅读。Awesome-TTRSS 内有集成相应的插件和服务程序。
不过原作者是使用 node.js 编写的服务端,翻译数据库得不到及时更新,如翻译后还是写的是义大利而不是意大利。而且 docker image 体积 100+M,内存占用也较大。我在考虑用 Go 语言重写 OpenCC 的服务端并兼容 TTRSS 的 OpenCC 插件,并加入 CI 自动从上游同步翻译数据库。
0x04 为不支持 RSS 的网站自制源
繁茂如 RSSHub 也不能保证拥有所有站点的 RSS 源。对于自制源,网上的方案大多数为使用 Feed43 和 Feedburner,但是人家是商业服务,虽然使用确实方便,但说到底还是为了商业。白嫖用户限制多不说,天知道哪天会有 break change 或者直接被墙或者跑路。最稳妥的做法还是自建。
手写爬虫程序简单灵活,不过后期维护难度较高而且难以复用。对于我想要订阅而有没有现成的源的网站,我的解决方案主要是两个:
1. 为 RSSHub 编写目标站点的规则,并 Pull Request 申请合并
RSSHub 除了提供众多现成的各类站点的 RSS 规则之外,也提供了快速构建一个站点的 RSS 源的常用工具类和模板。需要对 JavaScript 和爬虫技术有一定了解。很荣幸能提交了几个 pr 并且已经合并进了主分支,如 CQUT 的教务处通知和知乎的用户文章列表。
2. 使用 Huginn 为目标站点自制源
Huginn 是一个强大的 IFTTT 应用,用它来生成 RSS 源简直是大材小用(主要是他动辄 200M 的内存占用)。不过某些情况下我需要监视特定站点并在内容变化时得到通知,个人向为主,这类就不适合写 RSSHub 的规则。
使用门槛比 RSSHub 略低,可视化界面还是比较友好的,不过新手上手还是会有点困难,了解了 Huginn 的工作原理和基本的 Liquid 语法之后就手到擒来了。
3. 使用 feed43 和 rss-proxy 这类可视化工具自助生成 RSS 链接
手写解析规则还是太麻烦,很多网页结构很简单根本没必要单独花时间写一堆解析规则,而且有些时候只是想临时订阅一段时间或是订阅个很小的网站,不想大费周章,选择 feed43 这类工具不失为一个轻量又便捷的选择。不过feed43对免费账户创建的 RSS 并不保证稳定,时常无法连接甚至直接失效。在 Github 上发现一个不错的替代品rss-proxy,一个可视化的,快速自助生成站点 RSS 链接的工具。
填入目标网址就可以自动解析目标网页,程序会自动检测网页上的列表内容,可以自己选择要订阅哪个列表,然后就可以生成一个 RSS 链接。生成的 RSS 链接包括的信息有目标网址、要订阅的目标列表的节点信息和输出格式(RSS/ATOM)等,也就是说,rss-proxy 并不像 feed43 会把解析的规则存储在服务端,它是直接编码在 url 里面的!rss-proxy 开源支持自部署,不想用它提供的公用实例也可以自建,迁移零门槛。rss-proxy 也支持调用无头浏览器渲染异步获取数据的网页,可玩性很高。
->>>> rss-proxy 公用实例,可以点击体验下,还是很方便的
使用了一段时间体验挺不错,有个小问题就是对 UTF-8 以外的编码不太友好。
0x05 解锁海外 RSS 源
由于众所周知的原因,我国的互联网是不「互联」的。rsshub.app 部署在国外,现已基本无法直接访问。国内服务器上自建的 RSSHub 订阅如 Facebook 等国外站点更是不可行。为此我使用了 Clash 代理,并添加了一些公开的机场订阅,虽然速度和稳定性不是很高,但对于 RSS 这种需求还是绰绰有余的。又完善了一些爬墙的规则,比如对 google、facebook,rsshub.app 走代理,内网地址和 CN 的 IP 直连,反爬严格的网站完全走随机节点。一番操作下来,基本可以实现全球 RSS 订阅自由了 😁
0x06 RSS 订阅破 CloudFlare 五秒盾
如上所述,海外 RSS 源走公用机场可以解决国内的网络问题。但是很多站点会使用 CloudFlare 做 CDN 和防火墙,我们使用的公用机场其实一大半都是被用作非法用途的,IP 很多都在人家的黑名单里面,但凡通过那个节点访问 CloudFlare 保护的网站都会触发五秒盾防御,浏览器访问倒是没什么,但是可苦了 RSS。
google 了一番,没人写过我这个问题。。。人家都是爬虫绕过五秒盾,调包实现的破解。不过好在最终还是有了可行的解决方案:Clash 识别 CloudFlare 节点 IP 段,对于他家的节点,使用 Round-Robin 算法的 Load-Balance 策略走海内外随机节点,包括本机直连。
上面一句话有三个技术要点:
- 识别 CF 节点:CF 的节点遍布全球,把 IP 列表加到 Clash 规则集里面肯定是不现实的。不过好在人家家大业大都是买的 IP 段,官网也给出了所有节点的 IP 段,也就十个左右。
- Round-Robin:一种常见的负载均衡算法,简单来说就是把所有节点组成一个圆环,每次访问选择一个环上的节点,之后沿环方向移动一个特定步长,作为下一个要使用的节点,每次访问所使用的节点都不一样。另一种常用的算法是 Consist-Hashing,一致性哈希,相同的 url 拥有相同的哈希值,根据哈希值来选择的节点是一样的,同一个 url 会使用同一个节点。对于上文提到的场景,要实现反反爬虫,那必须选择 Round-Robin 算法。
- 包括本机节点:如上文所述,触发五秒盾的原因是那些公用机场的 IP 都不大干净,但是我用来部署 RSS 这些东西的自用的服务器没有这个问题,只有网络问题 😂。使用本机作为随机节点的兜底,即便特殊情况下所有的公共机场都是脏 IP,但是本机能直连东亚和美西的 CF 节点,还是可以保证 RSS 的可用性。
可能的改进:匹配到 CF 节点,选择从本机连接东亚的连接较好的 CF 节点来请求目标站点的内容,可以一次解决那两个问题
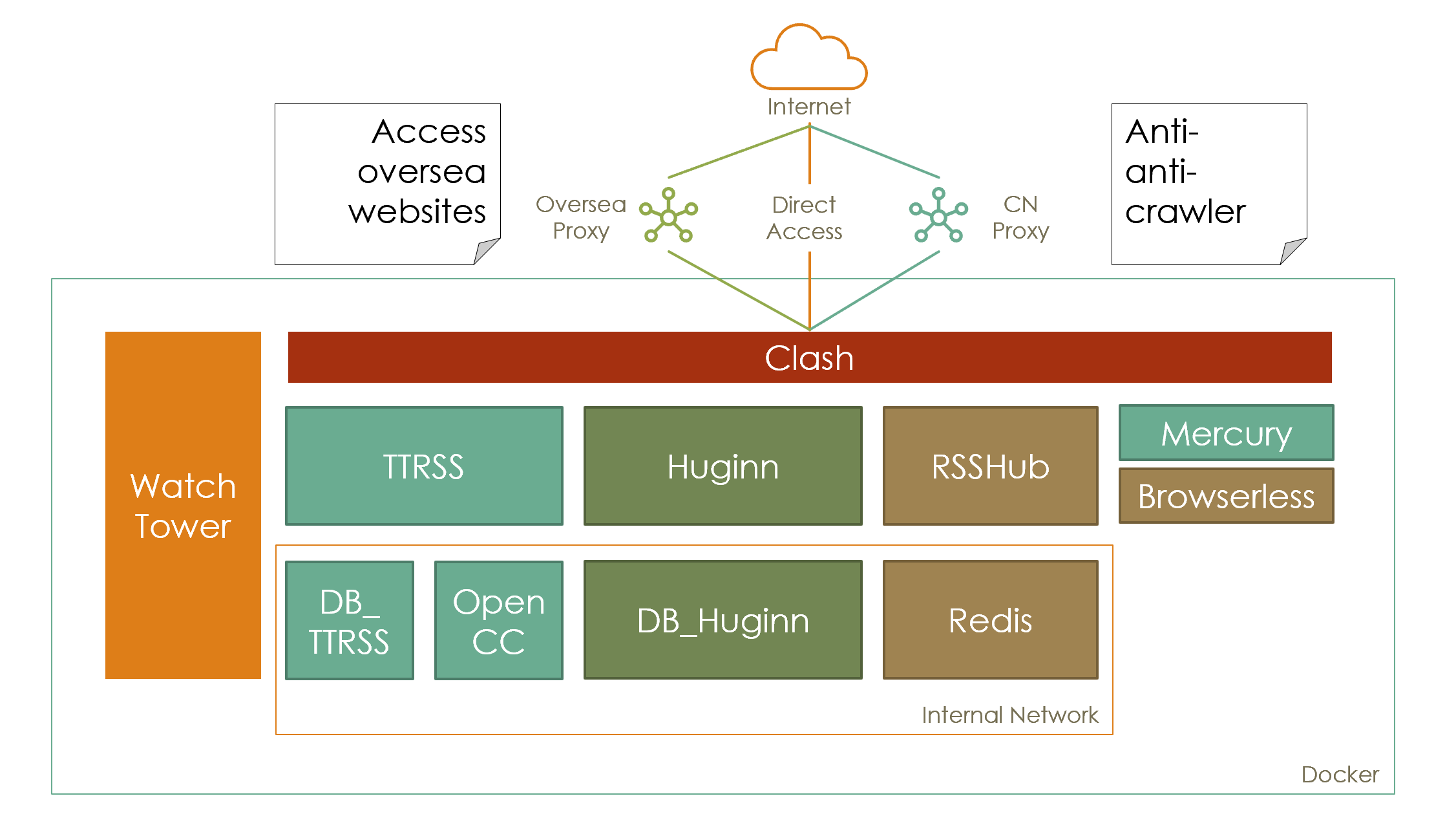
以上都被我整合进了我的 Github 项目 RSSman X
RSSman X 基于 docker-compsoe 提供容器化 TTRSS 与 RSSHUB 等组件的一键部署,整合实用组件为你带来最佳 RSS 体验
Feature:简单一键部署,常用组件整合,自动更新支持,服务健康自检支持,海外站点 RSS 解锁
感兴趣的朋友可以关注一下 🍺